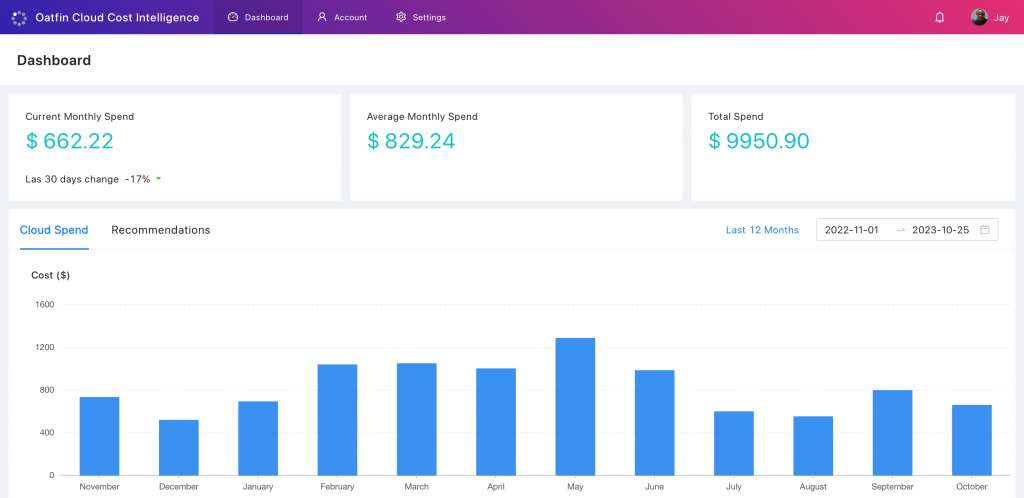
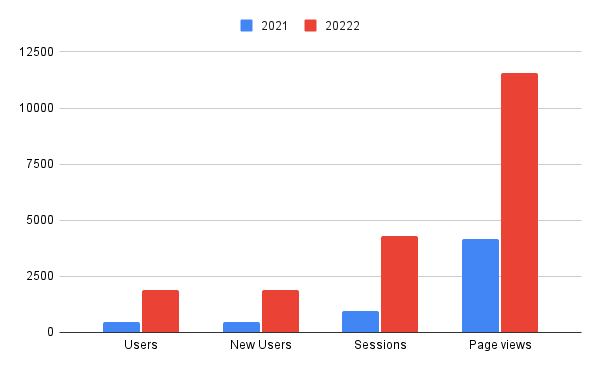
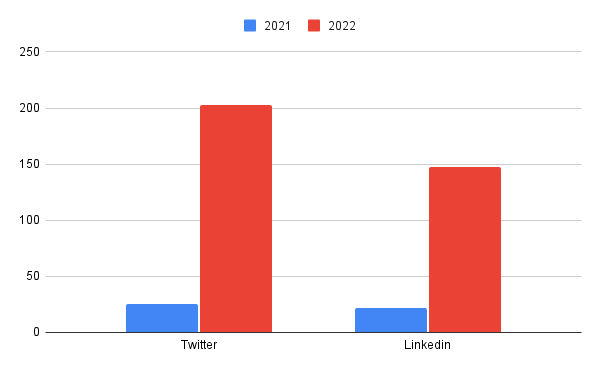
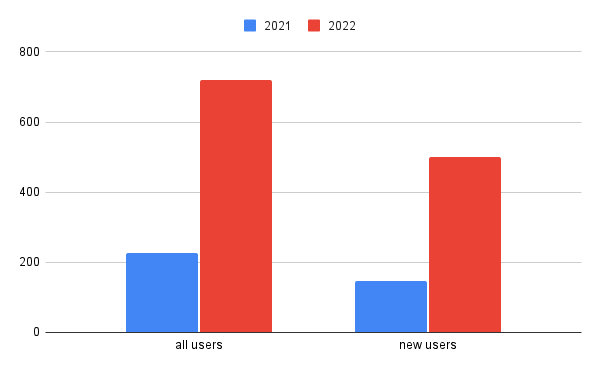
At Oatfin, we’ve been hard at work crafting a robust architecture that powers our web applications to handle millions of concurrent users and deployments seamlessly. In this blog, we’re thrilled to unveil the architecture behind the scenes, showcasing the technologies and strategies that drive our platform’s success.
Architecture Overview:
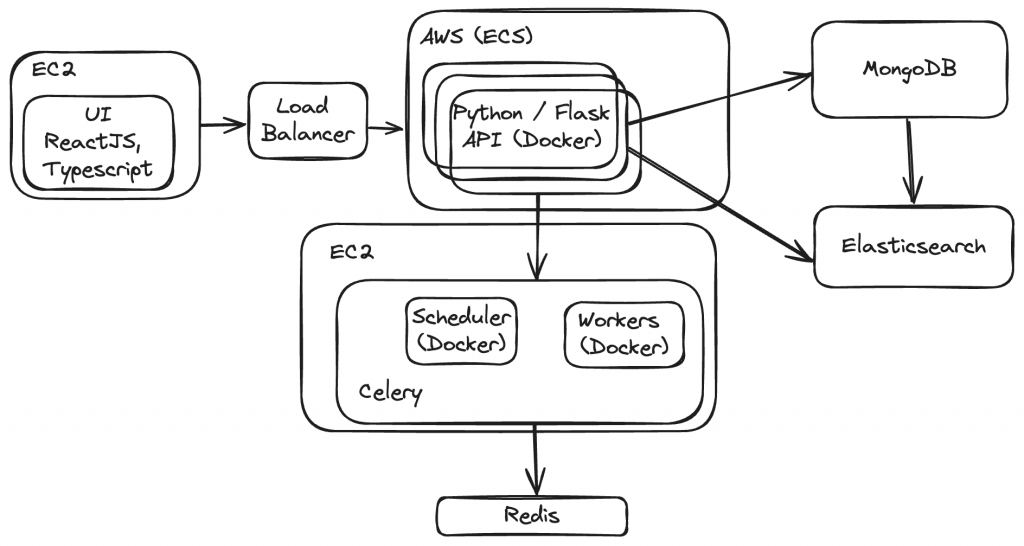
Let’s dive into the heart of our architecture. At Oatfin, we’ve crafted a solid foundation comprising key components:
- React, Typescript UI deployed on an EC2 instance: Our user interface is built using React and Typescript, providing a seamless and dynamic user experience. Deployed on Amazon EC2 instances, our UI delivers high performance and responsiveness to users worldwide.
- Python, Flask API using Docker and deployed using AWS Elastic Container Service (ECS): Powering our backend, we rely on Python’s robustness and the elegance of Flask to develop our APIs. Leveraging Docker containers, we ensure consistency and scalability in our deployments. AWS Elastic Container Service (ECS) manages our containerized applications, offering effortless scalability and reliability.
- MongoDB database using MongoDB Atlas: Data is the lifeline of any application, and at Oatfin, we entrust MongoDB to store and manage our data efficiently. With MongoDB Atlas, we enjoy the benefits of a fully managed database service, including automated backups, security features, and seamless scalability.
- Elasticsearch for indexing and searching documents: Searching and indexing documents is a breeze with Elasticsearch. We utilize its powerful search capabilities to enhance the discoverability of content within our applications, delivering fast and relevant results to our users.
- Celery, Redis task queue, and scheduler running inside Docker and deployed on an EC2 instance: Task queuing and scheduling are essential for handling background processes and asynchronous tasks. With Celery and Redis, we orchestrate our tasks efficiently, ensuring optimal performance and resource utilization. Docker containers simplify the deployment and management of Celery and Redis components, while EC2 instances offer the flexibility and scalability we need.
Scalability and Deployment:
One of the hallmarks of our architecture is its scalability. By leveraging cloud-native technologies and best practices, we’ve built a platform that can effortlessly scale to meet growing demands. Whether it’s handling spikes in user traffic or deploying updates seamlessly, our architecture is designed to adapt and grow with ease.
Our deployment process is streamlined and efficient. We deploy our React UI on EC2 instances, containerize our Flask API using Docker, and leverage AWS ECS for orchestration and scaling. MongoDB Atlas and Elasticsearch further simplify our deployment, offering managed services that eliminate infrastructure overhead.
Challenges and Future Improvements: Of course, building and scaling a complex architecture like ours comes with its share of challenges. From optimizing performance to ensuring security and reliability, we continuously strive to overcome obstacles and improve our platform.
Looking ahead, we’re excited about the future possibilities. We’re exploring new technologies, optimizing our architecture for even greater performance, and refining our processes to deliver an exceptional user experience.
At Oatfin, we’re proud of the architecture we’ve built, and we’re excited to share it with you. Our commitment to scalability, reliability, and innovation drives us forward as we continue to push the boundaries of what’s possible. Thank you for joining us on this journey, and we look forward to shaping the future of technology together.